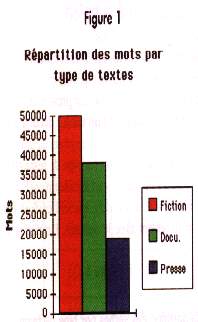
Nous profitons de la bibliothèque d'ELSA et de son volume pour mener quelques investigations dans le fonctionnement de la langue. Avec environ 300 textes, 700 000 signes, 110 000 mots, sa taille commence à être conséquente (à titre de comparaison, les Pensées de Pascal "font" 100 000 mots). Mais nous connaissons aussi la répartition interne de ses trois types de textes ; la fiction par exemple, avec 50 000 mots, représente environ la moitié des mots mais seulement 40% des textes. De la même façon, nous avons accès à la distribution entre les séries d'exercices (présentées dans le "dossier" cité en introduction ainsi que dans les A.L. nø52 de décembre 1994). Nous rappellerons juste ici que les textes d'ELSA sont, de l'avis des enseignants et des bibliothécaires, assez représentatifs des textes que sont susceptibles de lire des élèves du CE2 à la 5ème. Nous allons donc essayer d'en donner une image la plus précise possible.
Cinq points vont maintenant être abordés : la
nature des phrases ; la nature des mots ; les verbes ; les formats
particuliers des phrases et enfin l'énonciation.
Nous avons calculé les valeurs des variables dans les trois
types de textes (fiction, presse, documentaire) et dans les 5
séries comprenant des textes (c'est à dire B, D, E, F,
T). Nous avons ensuite examiné si les différences des
valeurs obtenues étaient dues à un effet particulier ou
si, au contraire, elles n'étaient que le reflet de
particularités hasardeuses (différenciation
exécutée à l'aide du test statistique du Khi deux).
Nous n'avons retenu que les variables qui se différencient de manière significative dans les trois types de textes. Ce test du khi deux indique également la répartition observée et la répartition théorique, celle qui existerait si les répartitions étaient équivalentes. Les graphiques représentent donc la différence entre les pourcentages observés et les pourcentages théoriques (*).
Nous présenterons également la valeur pour l'ensemble des textes, et, si elles existent, les valeurs calculées par J.P. Bronckart et son équipe dans Le fonctionnement des discours ou par Jean Foucambert et son équipe dans le cadre de la recherche sur la Genèse du texte.
I. La nature des phrases.
Nous avons calculé la répartition des différents types de phrases (déclaratives, interrogatives, négatives, impératives, exclamatives et nominales).
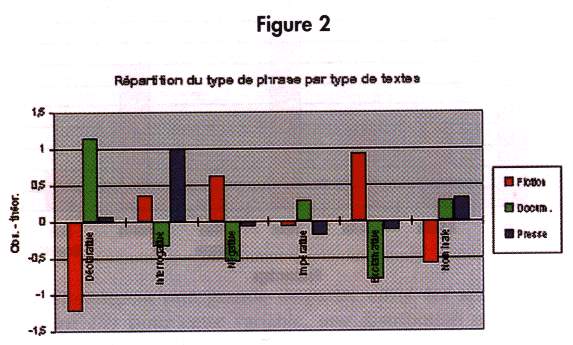
La différence des valeurs obtenues dans chacun des trois types de textes est significative (P. = 0.00%). La figure 2 montre les différences entre effectif observé et effectif théorique :
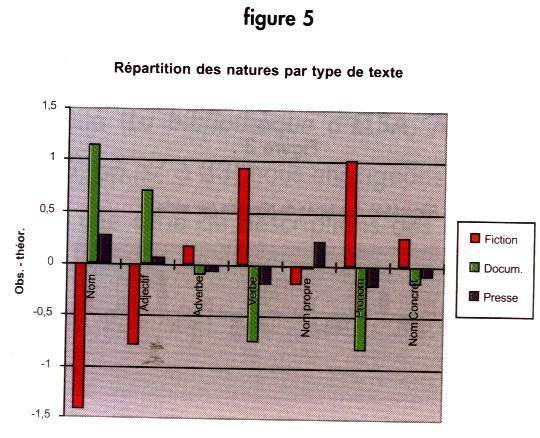
chaque groupe de trois "bâtons" représentant la répartition d'une donnée dans les trois types de textes. Ainsi peut-on lire que par rapport aux autres types, il y a peu de phrases déclaratives dans les fictions (valeur négative) contrairement (et toujours comparativement) aux documentaires. De même, peut-on remarquer que la presse se caractérise par une forte présence de phrases interrogatives et nominales (même si cette dernière catégorie "pèse" beaucoup moins lourd que, par exemple, celle des phrases déclaratives).
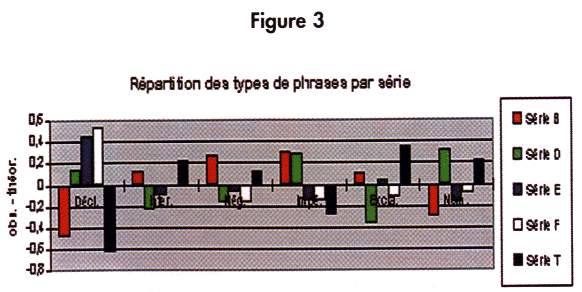
La répartition des types de phrases par série (figure 3) est aussi significatives (P. = 0.00%). On note, par exemple, un grand nombre de phrases déclaratives dans les séries E et F. Hasard ou volonté délibérée ?
(À titre d'indication, la longueur moyenne de phrases est de 13 mots et remarquablement homogène dans toutes les séries comme dans tous les types.)
II. La nature des mots.
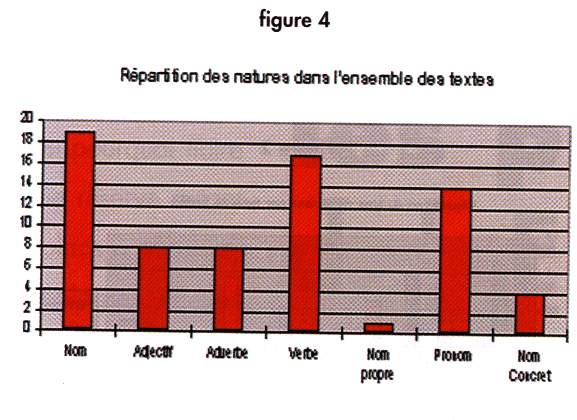
Sont pris en compte les catégories grammaticales suivantes : les noms, les adjectifs, les adverbes, les verbes, les noms propres et le nombre de pronoms. Les différences de répartitions pour l'ensemble des textes (figure 4) et entre les types de textes (figure 5) sont significatives (P = 0.00%).
III. Les verbes.
Ont été retenues 10 modalités verbales : infinitif - participe présent - gérondif - présent, imparfait, passé simple, futur simple et passé composé de l'indicatif, impératif présent et subjonctif présent... d'autres temps ayant de trop faibles occurrences.
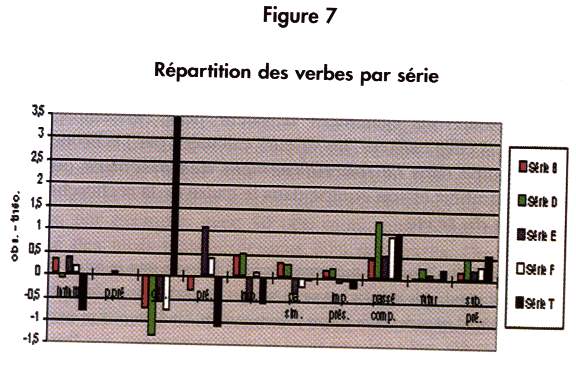
Les différences de répartition tant par type de texte (figure 6) que par série d'exercices (figure 7) sont significatives (P. = 0.00 %). On voit que les types de textes se différencient exclusivement par la manière dont ils jouent avec le présent, l'imparfait et le passé simple.

Le tableau ci-dessous permet de comparer les pourcentages des verbes (pour 5 temps retenus) dans l'ensemble des textes d'ELSA à ceux indiqués par J.P. Bronckart dans Le fonctionnement des discours et par Jean Foucambert à partir de l'analyse linguistique (menée dans le cadre de la recherche Genèse du texte) de 550 textes majoritairement écrits en situation scolaire par des enfants et des adolescents. LA aussi, on peut voir que la bibliothèque d'ELSA est assez proche du fonctionnement général des discours (Bronckart). En revanche, l'usage que les enfants font des temps lorsqu'ils écrivent ne suit pas les mêmes répartitions.
| Temps | Genèse | Broncart | Elsa |
| Présent | 60.88 | 42.41 | 41.75 |
| Imparfait | 9.95 | 15.54 | 12.17 |
| Passé simple | 4.61 | 9.35 | 7.88 |
| Passé composé | 12.37 | 4.95 | 7 |
| Futur simple | 3.07 | 2.14 | 2.51 |
IV. Les formats particuliers de phrases.
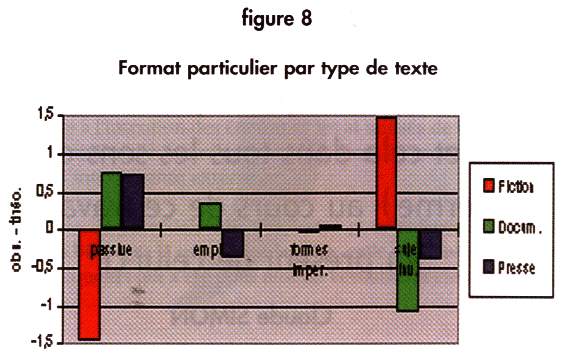
C'est ici encore une approche classique des phrases. On y cherche celles qui ne sont pas sur la forme sujet + verbe + complément et où le sujet est l'acteur de ce qui suit. On y décompte donc les formes passives (complètes et incomplètes), les emphases, les formes impersonnelles et les sujets inversés. La différenciation par type (figure 8) se trouve gratifiée d'une bonne probabilité (P.= 0.00). Pas de passif dans la fiction, mais beaucoup de sujets inversés, par exemple.
V. L'énonciation.
Trois catégories : les interlocuteurs, les modalisateurs et les marques de l'argumentation.
A) Les interlocuteurs.
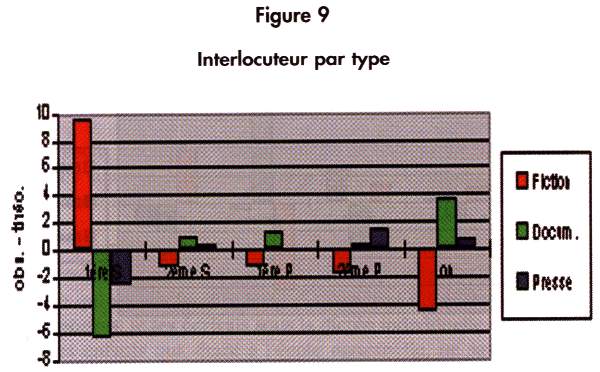
Toutes les marques pronominales renvoyant aux 1ères et 2èmes personnes du singulier et du pluriel sont prises en compte dans ce calcul (P. = 0.00%). On note particulièrement l'importance du récit à la 1ère personne du singulier.
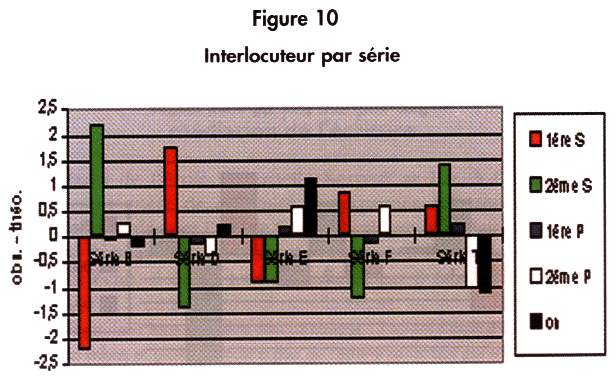
On remarquera une grande disparité entre les séries d'ELSA (figure 10) pour cette variable, une distribution un peu irrationnelle. (P. = 0.00%)
B) Les modalisateurs du discours.
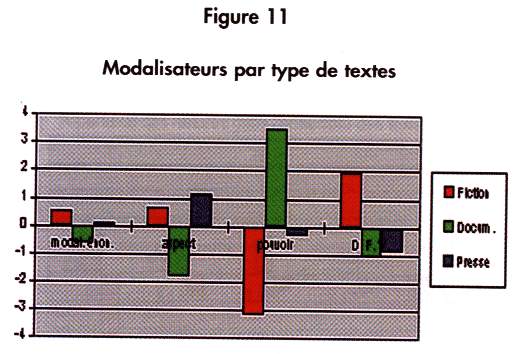
Les modalisateurs du discours sont au nombre de quatre : les modalités d'énoncés (qui introduisent une distance par rapport à ce qu'on peut bien dire, comme " Il semble que ... "), les auxiliaires d'aspects (qui précisent un moment du déroulement de l'action, comme " Il commença à marcher... "), les auxiliaires devoir, falloir, vouloir, et enfin l'auxiliaire pouvoir. La différenciation entre les types (figure 11) donne une probabilité de 0.00%. La différence par série n'est pas suffisamment significative pour être exposée ici.
C) Les marques de l'argumentation.
Il s'agit des connecteurs d'argumentation au sens qu'en donne Ducrot, les superlatifs et les comparatifs, enfin les exclamatives et les interrogatives. La différenciation (figure 12) donne une probabilité de 0.00%.

Quelques valeurs prises dans cette partie peuvent être comparées à celles calculées pour le "Fonctionnement des discours", et pour la recherche "Genèse du Texte". Nous les présentons dans le tableau suivant, en pourcentage sur le nombre de mots, sauf mention (/V) :
| Genèse | Broncart | ELSA | |
| Pronoms 1è pers. sing. | 2.48 | 1.63 | 1.51 |
| Pronoms 2è pers. sing. | 1.15 | 0.4 | 0.58 |
| Pronoms 1è pers. plur. | 0.33 | 0.66 | 0.28 |
| Pronoms 2è pers. plur. | 0.21 | 0.5 | 0.28 |
| On (M) | 0.76 | 0.64 | 0.40 |
| Modal.Enoncé (/V) | 0.03 | 0.05 | 0.46 |
| Auxil. Aspect (/V) | 0.57 | 0.91 | 0.97 |
| Auxil. Pouvoir (/V) | 1.87 | 3.38 | 0.82 |
| Auxil. D.E.V (/V) | 2.13 | 2.91 | 1.81 |
Denis FOUCAMBERT
(*) La taille d'un "bâton" dans un histogramme marque la
différence entre ce qui est observé et ce qui serait
attendu si le texte (ou le type de texte) se comportait comme
l'ensemble des textes. Si un "bâton" est au-dessus de la ligne
(valeurs positives) il indique, pour ce qui concerne la variable
étudiée, qu'il y a plus que ce qui est attendu et
inversement, si un "bâton" est en-dessous de la ligne (valeurs
négatives) qu'il y a moins.
Attention, la taille des "bâtons" témoigne seulement de
l'importance des différences. On voit, par exemple, dans la
figure 6 que le présent crée des différences
importantes entre les types de textes alors que le passé
composé n'en crée pas. Pour autant, cela ne dit rien de
la fréquence d'emploi du présent et du passé
composé.